




Data and AI are vital to our work at Marshmallow. Using data, we can keep our prices affordable, offer cover to underserved communities, keep improving our customer experience, and so much more.
As an insurance company, we’re data-rich. We have 100s of data points for each quote we generate, and we generate millions of quotes each week. But we want to get more value out of the data we’ve got, enhancing our capabilities to be world-class leaders in data analytics.
Over the next few years, we’re planning to launch new products in new markets, reaching hundreds of thousands more customers. Having the right data, and using it in effective ways, will be key to our success. So, we need to make sure our analysts, data scientists, and engineers across the business have the tools to do their jobs well. That starts with having a strong data team structure!
Why do we need a new data team structure?
The problems we’re trying to solve with our new data team structure:
- Our analysts are currently spread across the business. We want to give them a standardised way of working, with clear progression and relevant training.
- We want to have a clear end-to-end data strategy and data culture that is present throughout the business, from data ingestion through to analytics and decision making.
How we’re solving these problems
📊 Creating a community of data analysts
Currently, our analysts work across the company, within their specific teams. That’s incredibly useful, but we think we can empower them to do even better work by bringing them together under a Data Analytics Manager.
Our Data Analytics Manager will help build a data community of analysts. As a community, our analysts will discover the best ways to work and train, while actively up-skilling each other.
Day to day, each analyst will still work closely with their individual team - whether that’s Ops, Fraud, Claims, etc., but they’ll report into the Data Analytics Manager. Working with the Data Analytics Manager will allow our analysts to understand the larger, company goals.
👩💻 Empowering product teams to access and understand data
We want to create a culture of self-served data literacy, where all of our teams can continually access and understand data relevant to their work.
So, for the first time ever, we’re hiring product analysts who will be embedded into our product teams such as the Growth team.
These product analysts will work alongside their team of product managers, engineers, researchers, and designers, helping everyone to access and understand data from a product point of view. That way, every team can make data-driven decisions without having to reach out to analysts or data engineers from across the company. This enables greater autonomy by empowering decision-making within the teams that have the most project context.
As a result, these new product analysts will help:
- Break down silos in the company
- Teach others how to access, understand and manipulate data
- Make sure that our data is accurate and trustworthy
- Ensure relevant KPIs and measures are established
🟠 Building a centralised data hub
We want our data strategy to be uniform across the company, and for everyone to align with our culture of data. So, we’re building a centralised data hub to help guide and inspire the work of our analysts, data scientists, and data engineers.
The data hub will make sure that data is collected, presented, and used across the company consistently, in the best possible way.
As a result, we’ll have a more cohesive end-to-end strategy shaping everything from product data collection through to predictive modeling and analytics.
What does the new team structure look like?
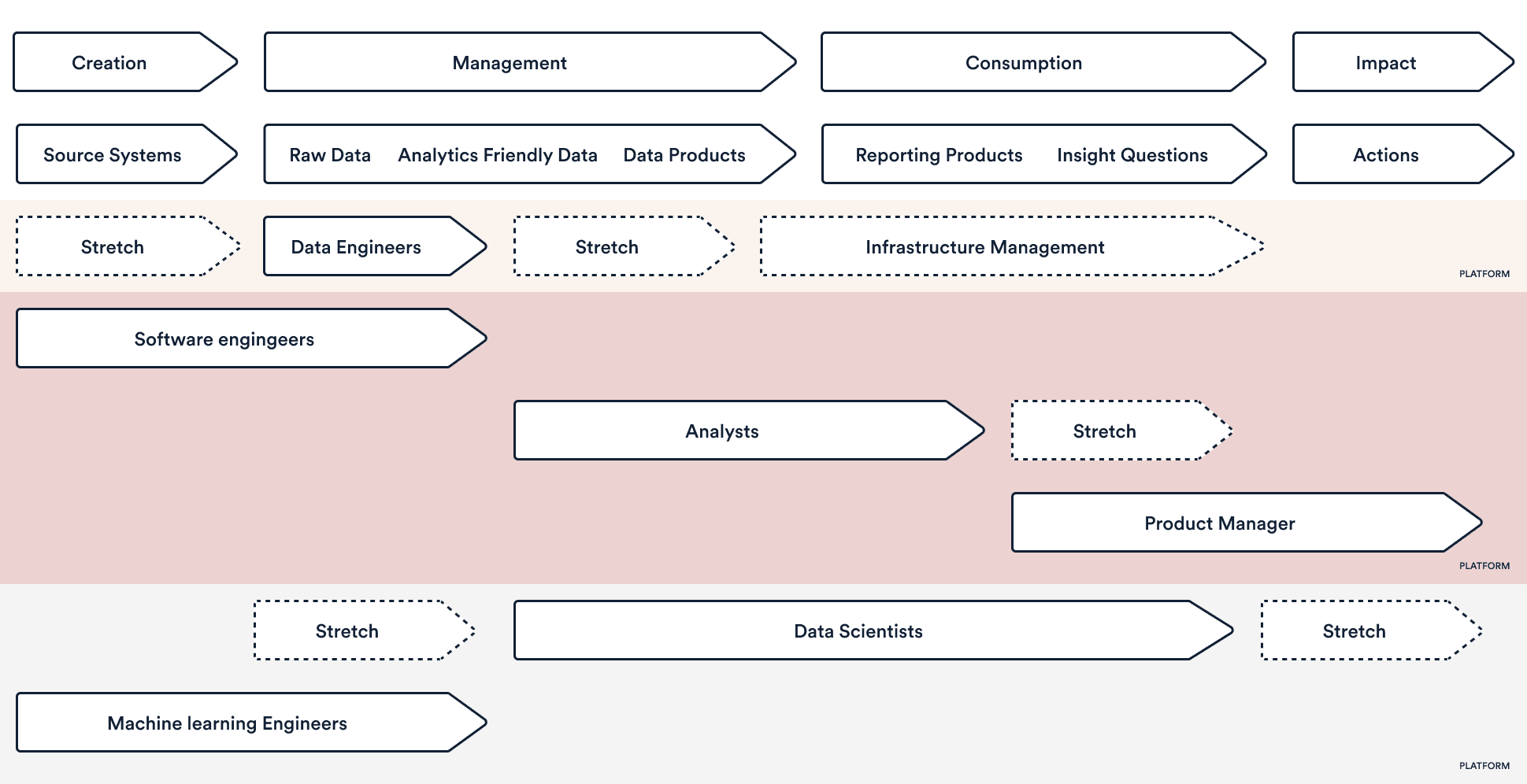
Different roles in the data team (data engineers, ML engineers, data scientists, data analysts, etc.) will be responsible for different (and sometimes multiple and/or overlapping) areas of data, ranging across creation, management, consumption, and impact.
The diagram below shows what tools and data types we’ll be using to source, manage and analyse data, and which roles will use which specific tools.
If you take our Product Analysts, for example, they’ll be using our analytics friendly data and data products, consuming it via our reporting tools, and sometimes stretching themselves in their role to drive the impact of that data. Software engineers, on the other hand, will work with our source systems, creating data and managing our raw data.
Speed is what keeps Marshmallow competitive, and allows us to keep pioneering in the insurance space! As a business, we want to get as much real-time data as possible, so that both our people and automated models can draw quick conclusions from data and affect change fast!
But speed requires a solid data platform. Our new data team structure will provide just that. By working closely with their product teams, and as part of the data community, our analysts will have more ownership over their team’s data and how it’s delivered to the rest of the business. While our data scientists will be able to build models that they can deploy themselves, experiment with, and get value from, fast. All vital ingredients for innovation!
Want to be part of our new data team? Take a look at our current openings here!